Purging Strategies in Oracle SOA Suite 12c
Purging the product database is one of the most critical tasks for ensuring the stability and performance of SOA/BPM Suite production environments. However, as important as this may be, it ends up usually being neglected or even completely overlooked, that is, until the shit literally hits the fan and then we’re just scrambling to save the operation and control the damage.
Having a consistent purging strategy should always be a priority and part of the product’s administration cycle, which means that we need to have accountability to go with streamlined procedures, including patching, backup, documentation, etc. This has been true for every version of the product, from 10g to 11g, and now also in the new 12c version; and even though we now have the nice auto-purge feature in EM (https://blogs.oracle.com/ArdaEralp/entry/oracle_soa_12c_auto_purge), we shouldn’t be over-confident about it, or at least not yet.
So, there are two very important things which will allow you to design and implement a purging strategy for SOA Suite:
Understanding the product database - which doesn’t mean you have to study the whole schemas, but rather identify a handful of relevant tables, columns and relationships belonging mainly to the
You can look into the official documentation and find some scattered though valuable information about this. Also, Oracle’s SOA Proactive Support, A-Team and some community standouts have already written very useful pieces containing detailed explanations, examples and every-day queries:
http://www.ateam-oracle.com/purging-and-partitioned-schemas/ https://blogs.oracle.com/soaproactive/entry/soa_suite_11g_purging_guide https://blogs.oracle.com/ateamsoab2b/entry/list_of_all_states_from https://technology.amis.nl/2015/01/29/oracle-soa-suite-12c-multithreaded-instance-purging/ https://soaarchitecture.wordpress.com/2013/02/11/soa-infra-usefull-everyday-queries/
The next link for example will take you to a very thorough, four part series which walks the reader through the intricacies of the BPM’s engine DB related activities (particularly in parts 2 to 4).:
http://www.ateam-oracle.com/bpm-process-instances-faults-rollback-recovery-part-1/
Most of the information here applies also to SOA composites (BPEL, Mediator, Human Workflow), so its definitely worth a look even if you’re not implementing BPM.
These are great resources, but the rest is up to you, as there is no substitute for assertiveness, practice and self-experience in a subject like this.
These strategies should also evolve as the product does. Even though some fundamental elements remain the same through version changes, many others change, so an outdated approach won’t be as effective. For example in version 12c, it’s important to identify the changes in the way instance data is being stored in comparison with 11g. With some of our customers which are already in 12c, we have been facing this kind of challenge, which definitely takes us out of the comfort zone but is also a lot of fun and a learning experience.
Another advantage of understanding all of this, is that at some point, most running implementations could run into troublesome scenarios which will require dehydration store troubleshooting. Whether this is the result of a bug, product defect, implementation mistake, system entropy, unexpected peak or other, it will be much better if we at least have an idea where to start looking rather than not having a clue at all about what’s happening.
Let’s take a look at an example based on one of our most recent experiences:
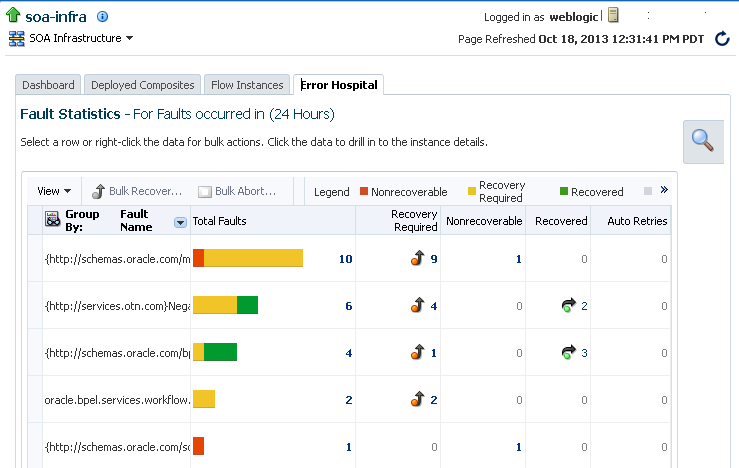
We have some troublesome instances which have been accumulating overtime. We know they’re there because they will cause unstable behaviour and occasionally hug some resources, also producing a lot of output on the server logs. However, they won’t show up on the composite’s dashboards, recovery panel or on CUBE_INSTANCE, SCA_FLOW_INSTANCE tables. So we could call these “ghost” instances, which are toxic to our environment but are difficult to pin down and terminate.
After a while, we are able to find some traces of these instances, both in the database and the EM. It turns out that what’s making them so ghostly and problematic is that they’ve all lost their conversation IDs.
This condition ensures that trying to delete them from EM won’t work, and it also makes them kind of invisible to the purging scripts, which have been executed regularly in this environment.
So we need to go into the DLV_MESSAGE table:
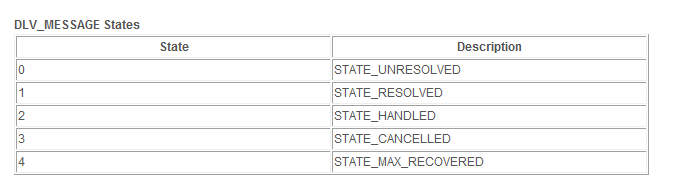
Which, if we have already taken a look into the links pasted above, we should know holds the state for every “Invoke” and/or “Callback” activity performed by our composite instances.
We’re querying for states “0” and “4” here, so once we’ve found what we’re looking for, we can take an instance, make sure that its FLOW_ID isn’t referenced in any of the other tables and then delete it manually with a simple query:
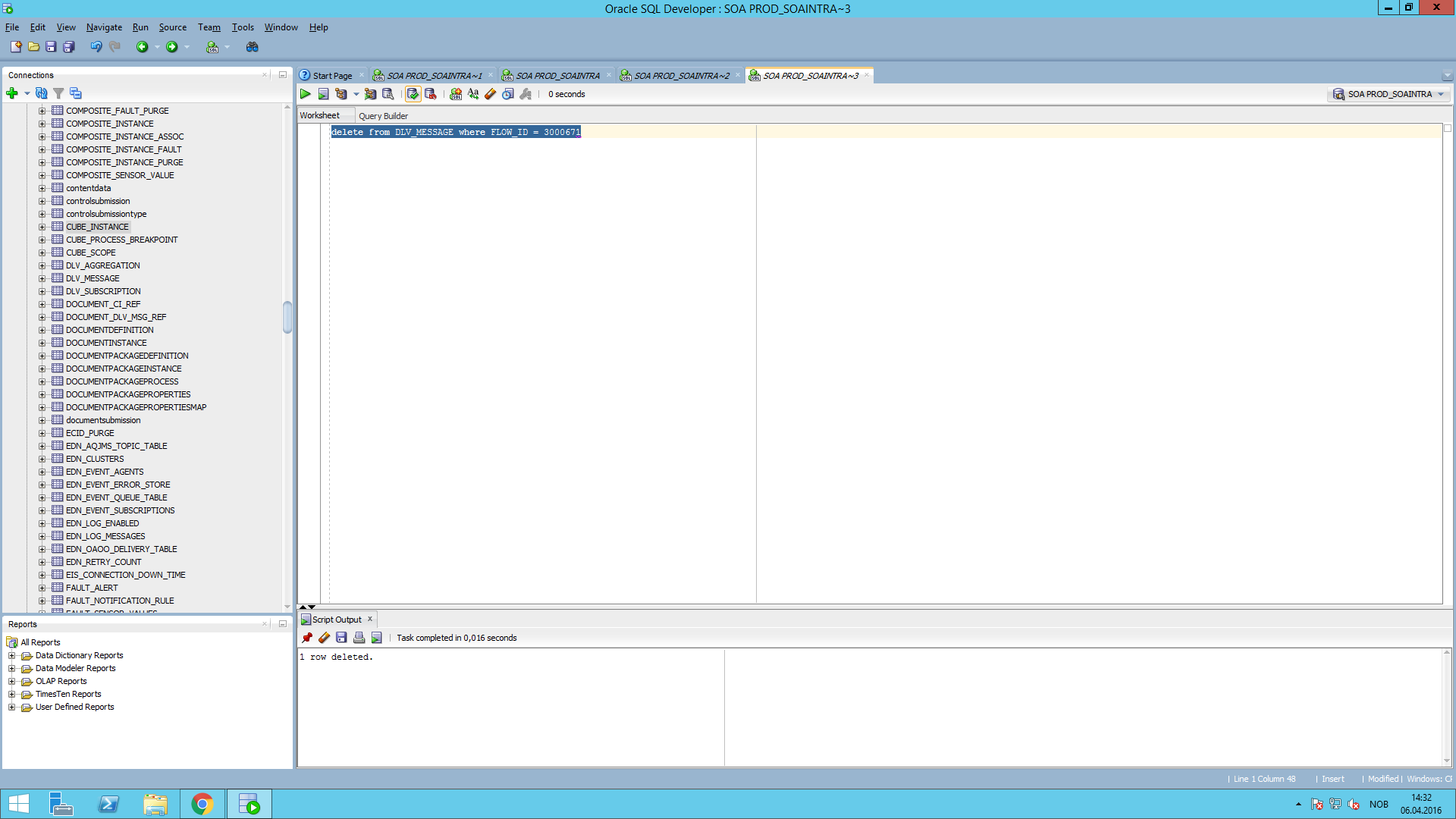
We can go back to EM and corroborate that the breadcrumbs left behind by this particular instance are gone too, so it won’t cause trouble anymore, so now, it’s time to delete the rest of these instances and leave a clean environment:
“delete from DLV_MESSAGE where state in (0, 4) and dlv_type in (1, 2) and component_name = ‘xxxxx’”
This kind of issues can be diagnosed and resolved really quickly with the appropriate knowledge, which reinforces the point we were trying to make in the paragraphs above.
Well, that’s all for this article; I certainly hope you found the post interesting and useful, thanks for reading!!