Testing Kafka-based applications
Testing Kafka-based applications

This blog is of continuation of discussion in these posts:
- Getting Your Feet Wet with Stream Processing - Part 2: Testing Your Streaming Application
- Testing Event-Driven Systems
Main purpose of this article is to share experience of testing Apache Kafka-based applications and data pipelines, using two different approaches.
Keywords in use:
- Kafka-based application - by kafka-based application I understand any application that uses
Kafka APIand communicates with kafka cluster. - Data pipeline - is a set of Kafka-based applications that are connected into a single context.
Examples are built using java and docker. For detailed information, check this repository on github.
Agenda
- Intro
- Unit tests of Kafka Streams application with kafka-streams-test-utils
- Integration tests with EmbeddedKafkaCluster
- End-to-end tests with Testcontainers
1. Intro
Many have faced a challenge to test applications that communicate with Kafka cluster. The common issues are how to write unit tests, how to automate tests for Kafka application in isolation and how to handle end-to-end and system tests for whole data pipeline.
When this article was written, there were several approaches, some of them still not resolved:
- KIP-139: Kafka TestKit library is still open. Once it will be ready, the Kafka community will have a proper test-kit.
- #26 Encapsulate EmbeddedSingleNodeKafkaCluster in a seperately-available maven/gradle/sbt dep. Kafka cluster in memory. When this post was published, there is an open issue for having release of embedded Kafka cluster. Yeva Byzek offers to use KafkaEmbeddedCluster in this blog-post. There is no existing release for these libraries. I decided to duplicate this part of code base and to build an internal module as an example.
- KIP-247 Add public test utils for Kafka Streams. This KIP is ready and has release for unit testing kafka streams topologies - kafka-streams-test-utils.
- Testcontainers - testing with docker containers.
2. Unit tests of Kafka Streams application with kafka-streams-test-utils
Kafka-streams-test-utils is a test-kit for testing stream topologies in memory without needing a Kafka cluster. Test-kit supports stateful operations and Avro serialization/deserialization via mocking of schema registry.
All that you need is TopologyTestDriver, which can be initialize on each test case where a topology is under test.
private TopologyTestDriver testDriver;
private MockSchemaRegistryClient schemaRegistryClient;
@Before
public void start() {
schemaRegistryClient = new MockSchemaRegistryClient();
}
@After
public void tearDown() {
Optional.ofNullable(testDriver).ifPresent(TopologyTestDriver::close);
testDriver = null;
properties = null;
}
I choose for testing topology with stateful operations and Avro.
// stateful
public static Topology topologyCountUsersWithSameName(
String sourceTopic,
String sinkTopic,
final Serde<Person> personSerdes,
final String storeName) {
final StreamsBuilder builder = new StreamsBuilder();
builder.stream(sourceTopic, Consumed.with(Serdes.String(), personSerdes))
.groupBy((key, value) -> value.getName())
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(storeName))
.toStream()
.to(sinkTopic, Produced.with(Serdes.String(), Serdes.Long()));
return builder.build();
}
Unit test of topology.
@Test
public void testTopologyAvro_statefulProcessors() throws IOException, RestClientException {
/** Arrange */
final String storeName = "same-name";
final SpecificAvroSerde<Person> serde = new SpecificAvroSerde<>(schemaRegistryClient);
final Map<String, String> schema =
Collections.singletonMap(
AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG,
"wat-ever-url-anyway-it-is-mocked");
serde.configure(schema, false);
// get topology
final Topology topology =
StreamProcessingAvro.topologyCountUsersWithSameName(
topicIn,
topicOut,
serde,
storeName
);
testDriver = new TopologyTestDriver(topology, properties);
final ConsumerRecordFactory<String, Person> factory =
new ConsumerRecordFactory<>(topicIn, new StringSerializer(), serde.serializer());
final ConsumerRecord<byte[], byte[]> inRecord1 =
factory.create(
topicIn,
"1",
Person.newBuilder()
.setId("id-1")
.setName("nikita")
.setLastname("zhevnitskiy")
.build()
);
final ConsumerRecord<byte[], byte[]> inRecord2 =
factory.create(
topicIn,
"2",
Person.newBuilder()
.setId("id-2")
.setName("nikita")
.setLastname("moscow")
.build()
);
/** Act */
testDriver.pipeInput(Arrays.asList(inRecord1, inRecord2));
final KeyValueStore<String, Long> keyValueStore = testDriver.getKeyValueStore(storeName);
final Long amountOfRecordWithSameName = keyValueStore.get("nikita");
/** Assert */
assertEquals(Long.valueOf(2), amountOfRecordWithSameName);
}
You can find full test example here and more examples in Apache Kafka documentation.
Pay attention to issue #877 - Passing Schema Registry URL twice to instantiate KafkaAvroSerializer.
3. Integration tests with EmbeddedKafkaCluster
Integration test is a way of how to test services in isolation but with required dependencies. Embedded Kafka cluster combines broker, zookeeper and schema-registry in one. To test asynchronous system I have chosen awaitility library. It is a useful tool for handling timeouts and asynchronous asserts.
public class ApplicationIT {
@ClassRule
public static final EmbeddedSingleNodeKafkaCluster CLUSTER =
new EmbeddedSingleNodeKafkaCluster();
@Test
public void clusterIsRunning() {
assertTrue(CLUSTER.isRunning());
}
@Test
public void testAvroConsumer() throws InterruptedException,
ExecutionException, TimeoutException {
String topic = "topic2";
CLUSTER.createTopic(topic);
final KafkaProducer<String, Event> producer =
new KafkaProducer<>(getProducerProperties());
producer
.send(
new ProducerRecord<>(
topic,
"id-3",
Event.newBuilder()
.setId("id-3")
.setType("type-3")
.setContext("context-3")
.build()))
.get(1, TimeUnit.SECONDS);
final KafkaConsumer<String, Event> consumer =
new KafkaConsumer<>(getConsumerProperties());
consumer.subscribe(Collections.singletonList(topic));
final ArrayList<Event> events = new ArrayList<>();
await()
.atMost(15, TimeUnit.SECONDS)
.untilAsserted(() -> {
final ConsumerRecords<String, Event> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord<String, Event> record : records)
events.add(record.value());
assertEquals(1, events.size());
});
}
}
4. End-to-end tests with Testcontainers
In context of Kafka-based applications, end-to-end testing will be applied to data pipelines to ensure that, first, the data integrity is maintained between applications and, second, data pipelines behave as expected.
Testing requires all integrated components of application to be up and running - in order to be able to test them with different scenarios.
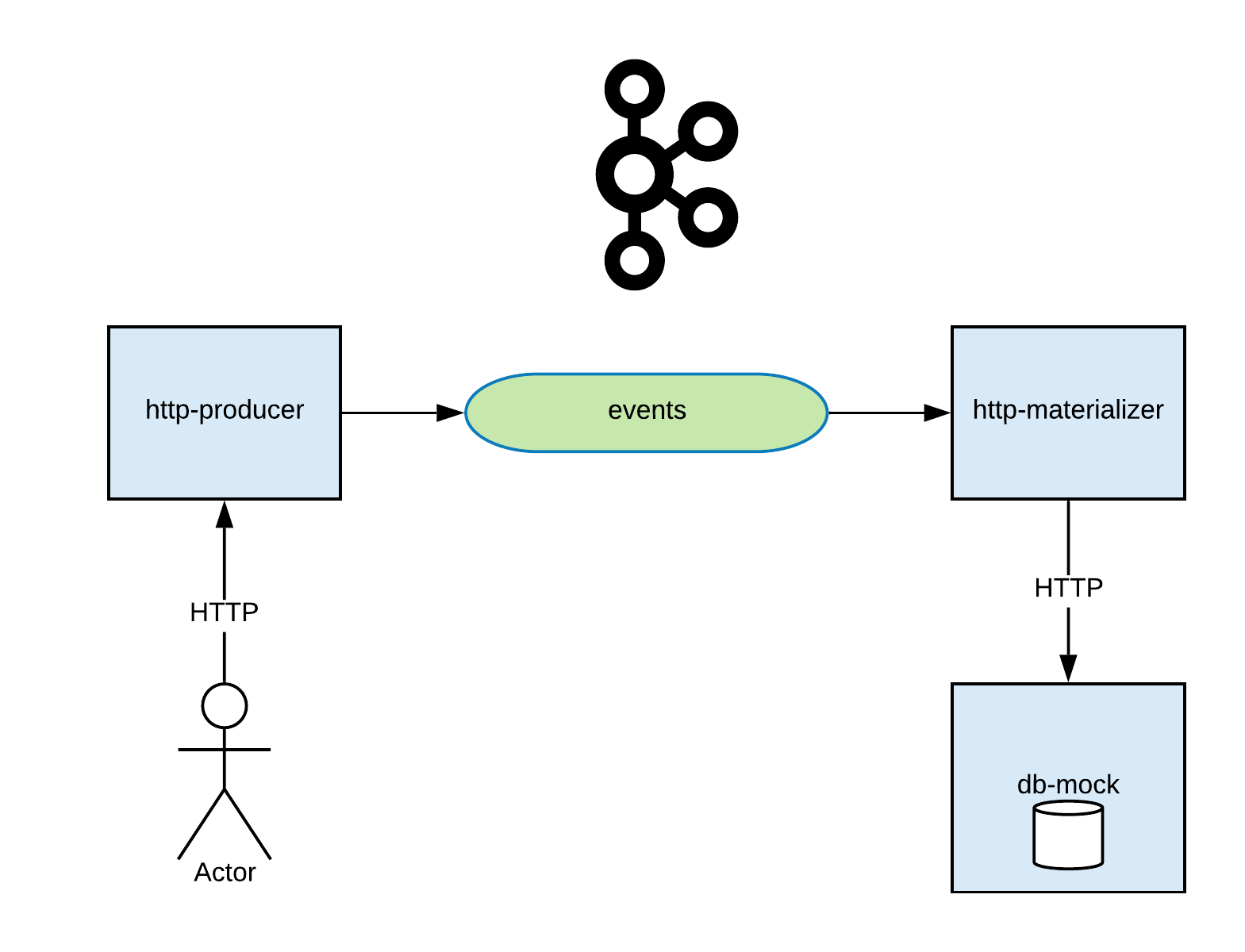
Requirements:
- Zookeeper
- Kafka broker
- Confluent schema registry
- Http-producer: REST producer
- Http-materializer: streams application, that downstreams topic data and RPC to another REST service
- Db-mock: REST service and db in memory (use .json file as persistent storage), all-in-one
I describe two approaches on how to prepare a container environment for testing. Both of them require a certain start-up sequence, namely: start a Kafka cluster first, wait until it is ready to receive requests, create required topics, register schemas and then run application services.
Approach 1: Declare each container separately
Each container is defined in the same test class under its own method and is run either @BeforeClass or in a static block.
Be aware about differences mentioned in documentation.
Testcontainers support Waiting strategies until containers are ready for test. Potential improvement could be implementation of health checks for each component in data pipeline.
/**
* Base test abstract class contains setup to
* initialize testing environment.
*/
public abstract class ContainersTestBaseIT {
// singleton containers https://www.testcontainers.org/test_framework_integration/manual_lifecycle_control/#singleton-containers
static {
final Network commonNetwork = Network.newNetwork();
setZookeeperAndKafka(commonNetwork);
setSchemaRegistry(commonNetwork);
setJsonServer(commonNetwork);
setHttProducer(commonNetwork);
setHttpMaterializer(commonNetwork);
}
// . . . rest code
}
To make containers interact with each other, you should put them with the same network. If one container depends on another container, you might need network alias to setup communication between them. You can provide your own network alias for container or use an already existing one. Aliases can be injected as environmental variable.
Container ports can be mapped to localhost while testing, if container’s port is exposed.
Files and directories can be also mapped as volumes on the classpath in container.
jsonServer =
new GenericContainer("zhenik/json-server")
.withExposedPorts(80)
// all containers put in same network
.withNetwork(network)
.withEnv("ID_MAP", "id")
// all containers put in same network
.withNetworkAliases("json-server")
// mount volume
.withClasspathResourceMapping(
"json-server-database.json", "/data/db.json", BindMode.READ_WRITE)
// waiting strategy
.waitingFor(Wait.forHttp("/").forStatusCode(200));
jsonServer.start();
// exposed to localhost
JSON_SERVER_EXPOSED =
"http://"+jsonServer.getContainerIpAddress() + ":" + jsonServer.getMappedPort(80);
// exposed to network with all containers
JSON_SERVER_INSIDE_DOCKER_ENV = "http://" + jsonServer.getNetworkAliases().get(0) + ":80";
Another useful feature is executing commands inside a container. It can be useful for creating a kafka topic before running streams application.
private static void createTopic(String topicName) {
// kafka container uses with embedded zookeeper
// confluent platform and Kafka compatibility 5.1.x <-> kafka 2.1.x
// kafka 2.1.x require option --zookeeper, later versions use --bootstrap-servers instead
String createTopic =
String.format(
"/usr/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic %s",
topicName);
try {
final Container.ExecResult execResult = kafka.execInContainer("/bin/sh", "-c", createTopic);
if (execResult.getExitCode() != 0) fail();
} catch (Exception e) {
e.printStackTrace();
fail();
}
}
Approach 2: Define containers in docker-compose file
Another approach is to prepare containers environment for testing is to define all the environment information in a docker-compose.yml. In this case Testcontainers manage composition of containers. All services share common network. Name of service uses as a network alias. This approach also supports waiting strategies.
Example of how to create topic in a docker-compose file can be found in Confluent examples.
/**
* Environment container contains composition of containers which are declared
* in docker-compose.test.yml file. Use a local Docker Compose binary.
* Waiting strategies are applied to `service-name` with suffix `_1`
*/
@ClassRule
public static DockerComposeContainer environment =
new DockerComposeContainer(new File("docker-compose.test.yml"))
.withLocalCompose(true)
.waitingFor("db-mock_1", Wait.forHttp("/").forStatusCode(200))
.waitingFor("schema-registry_1", Wait.forHttp("/subjects").forStatusCode(200))
.waitingFor("http-producer_1", Wait.forHttp("/messages").forStatusCode(200))
.withExposedService("db-mock_1", 80)
.withExposedService("http-producer_1", 8080);
Test
@Test
public void test_data_pipeline_flow_successful() {
String id = UUID.randomUUID().toString();
String from = UUID.randomUUID().toString();
String to = UUID.randomUUID().toString();
String text = UUID.randomUUID().toString();
MessageJsonRepresentation messageJsonRepresentation =
new MessageJsonRepresentation(id, from, to, text);
RestAssured.given()
.contentType(ContentType.JSON)
.body(messageJsonRepresentation)
.post(HTTP_PRODUCER_EXPOSED + "/messages")
.then()
.statusCode(202);
await()
.atMost(70, TimeUnit.SECONDS)
.untilAsserted(() -> {
MessageJsonRepresentation jsonPresentation =
RestAssured.given()
.get(JSON_SERVER_EXPOSED + "/messages/" + id)
.then()
.extract()
.as(MessageJsonRepresentation.class);
assertNotNull(jsonPresentation);
});
}
Conclusion
Hopefully, the described approaches and code examples will help to make testing Kafka client application easier. If you would like to contribute, just open a ticket on GitHub for ideas. Additionally, I would recommend to check Confluent’s blog that can be helpful to learn more about Apache Kafka.
Thanks to Jorge Quilcate, Sergei Egorov, Timur Samkharadze, Dasha Kormacheva.