Kafka - Confluent Schema Registry. Part 1
Introduction
Let’s talk about Kafka Schema Registry essentials.
Repository
Repository contains examples of schema evolution - full compatibility. poc-confluent-schema-registry-p1
Content:
- What is Confluent Schema Registry and why we need it?
1.1. Use case.
1.2. Compatibility types.
1.3. Avro serializer. - How to define schema?
2.1. In source code.
2.2. Using reflection.
2.3. Using json. - Schema evolution example.
3.1. Up kafka.
3.2. Up project. 3.2. Up project. - Important notes.
1. What is Confluent Schema Registry and why we need it?
Confluent Schema Registry is application, which manage compatibility and provides RESTful interface to preform CRUD operations. Schemas can be applied to key/value or both.
!NBissue680
Kafka producer will accept any mixture of Avro record types and publish them to the same topic.
Confluent schema registry is separate node. Kafka Consumer/Producer should have schema.registry.url and specific serializer/deserializer in properties,
if schema registry is in use.
Properties properties = new Properties();
properties.setProperty("schema.registry.url", "http://localhost:8081");
Confluent schema registry should be fault tolerant.
If node with schema registry not available, all clients will fail while producing/consuming (if no caching on client’s sides).
Kafka itself is not responsible for data verification, it stores only bytes and publish them.
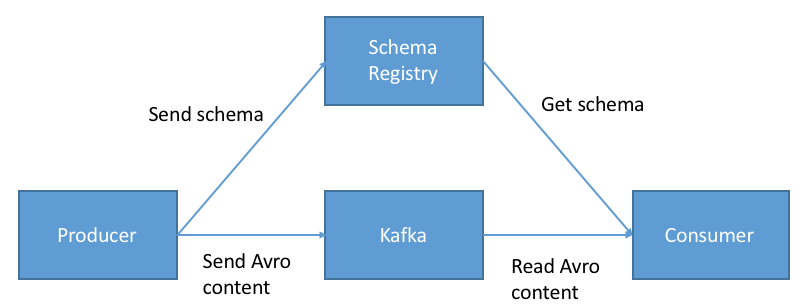
1.1. Use case
All of us faced with continuously coming new requirements from customers.
Sometimes we need to change data transfer objects: add additional fields or remove some of them,
which will cause mapping.
Schema registry is answer to - how to support schema versions and achieve full compatibility.
Do all those changes without breaking any dependent parts.
1.2. Compatibility types
| Type | Description |
|---|---|
| Backward | Old schema can be used to read New data |
| Forward | New schema can be used to read Old data |
| Full compatibility (Forward and Backward) | Both (Old & New) schemas can be used to read old & new data |
| Breaking | None of those |
Target is type Full compatibility.
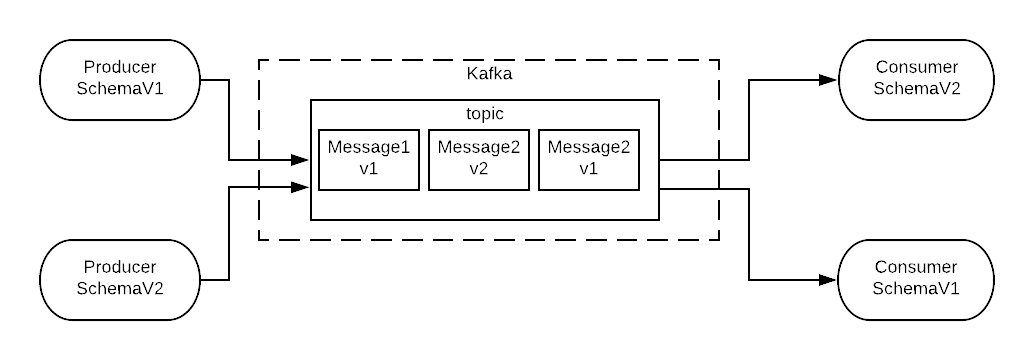
Full compatibility means that message which is produced with Old-schema can be consumed with New-Schema and opposite, message which is produced with New-schema can be consumed using Old-Schema.
1.3. Avro serializer.
Apache Avro is data serializer. This serializer is often used with Confluent Schema Registry for Kafka.
Avro key-features:
- Compressed data
- Types support
- Embedded documentation support
- Defined using json
- Avro object contains schema and data
- Shema evolution
2. How to define schema?
There are 3 ways how to define avro schema.
2.1. In source code.
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse("{\n"
+ " \"type\": \"record\",\n"
+ " \"namespace\": \"no.sysco.middleware.poc.kafkaschemaregistry.avro\",\n"
+ " \"name\": \"Business\",\n"
+ " \"version\": \"1\",\n"
+ " \"doc\":\"Business record contains name of company and list of customers\",\n"
+ " \"fields\": [\n"
+ " { \"name\": \"company_name\", \"type\": \"string\", \"doc\": \"Name of company\" },\n"
+ " {\n"
+ " \"name\": \"customers\",\n"
+ " \"doc\": \"List of customers\",\n"
+ " \"type\": {\n"
+ " \"type\": \"array\",\n"
+ " \"items\": {\n"
+ " \"type\": \"record\",\n"
+ " \"name\":\"Customer\",\n"
+ " \"fields\":[\n"
+ " { \"name\": \"first_name\", \"type\": \"string\", \"doc\":\"Customer name\" },\n"
+ " { \"name\": \"last_name\", \"type\": \"string\", \"doc\": \"Customer last name\" }\n"
+ " ]\n"
+ " }\n"
+ " }\n"
+ " }\n"
+ " ]\n"
+ "}");
2.2. Using reflection.
Use reflection. Make schema from POJO class. Do not forget to create empty constructor.
Schema schema = ReflectData.get().getSchema(ReflectedCustomer.class);
Pojo class example
Reflection full example
2.3. Using json.
The way is to define schema in file .avsc. Definition’s syntax is json.
Avro-maven-plugin generates classes from .avsc.
{
"type": "record",
"namespace": "no.sysco.middleware.poc.kafkaschemaregistry.avro",
"name": "Business",
"version": "1",
"doc":"Business record contains name of company and list of customers",
"fields": [
{ "name": "company_name", "type": "string", "doc": "Name of company" },
{
"name": "customers",
"doc": "List of customers",
"type": {
"type": "array",
"items": {
"type": "record",
"name":"Customer",
"fields":[
{ "name": "first_name", "type": "string", "doc":"Customer name" },
{ "name": "last_name", "type": "string", "doc": "Customer last name" }
]
}
}
}
]
}
3. Schema evolution.
Up kafka
Kafka should be UP, before perform next steps. There are two options how to do it:
Landoop- kafka cluster using ladoop images: with UI on http://localhost:3030, Connectors and additional tools.
docker-compose -f docker-compose.landoop.yml up -dConfluent- kafka cluster using confluent images
docker-compose -f docker-compose.confluent.yml up -d
Evolution
Build project and generate classes from business-v1.avsc and business-v2.avsc.
./mvnw clean package
Run producers in modules version1 and version2 in any sequential order to produce messages to one topic.
Run consumers in modules version1 and version2 in any sequential order to see consumption results.
4. Important notes.
These important notes help to achieve full compatibility
- Make your primary key required
- Give default values to all the fields that could be removed in the future
- Be very careful when using ENUM as the can not evolve over time
- Do not rename fields. You can add aliases instead
- When evolving schema, ALWAYS give default values
- When evolving schema, NEVER remove, rename of the required field or change the type
Refs & sources
Next posts
- More Complex examples
- Confluent Schema Registry with Kafka Streams API
- REST Proxy Schema registry